Reinforcement Learning (RL) is a branch of Artificial Intelligence where an agent (the model) and the environment are the basic components of it. The agent interacts with the environment by taking actions and receives rewards according to the impact of the action taken. The objective of the agent is to learn to behave in such a way as to maximize the expected rewards in the long term.
Basic understanding of RL
In this post, the example of Ms. Pacman is too complex to understand how Reinforcement Learning works. Thus, let’s introduce a simpler example.
Example
Imagine a red dot which can move into six directions : \(X, Y, Z, -X, -Y, -Z\). The agent is defined as the red dot which is more precisely a model such as a deep neural network. The directions are called actions and the agent can move each step by choosing one of its actions. The environment is defined as a 3D space where the agent has a position \((x, y, z)\). The state of the environment is the position of the agent. 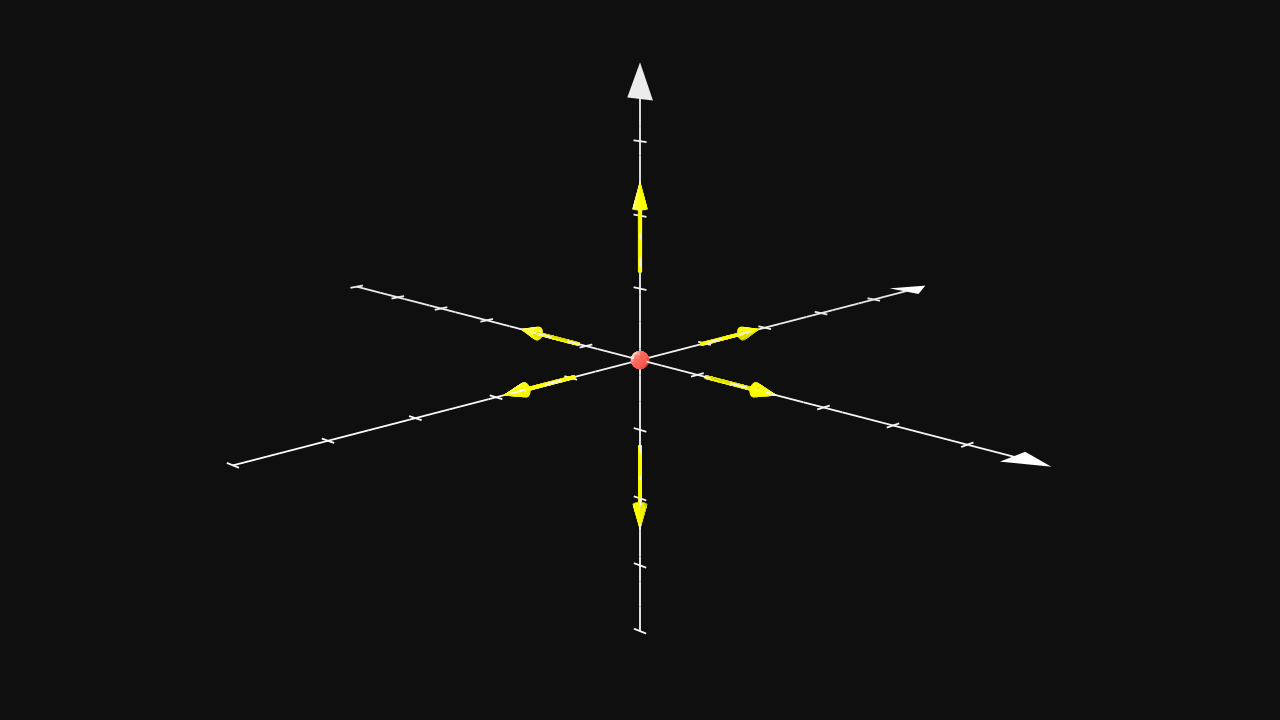
Goal
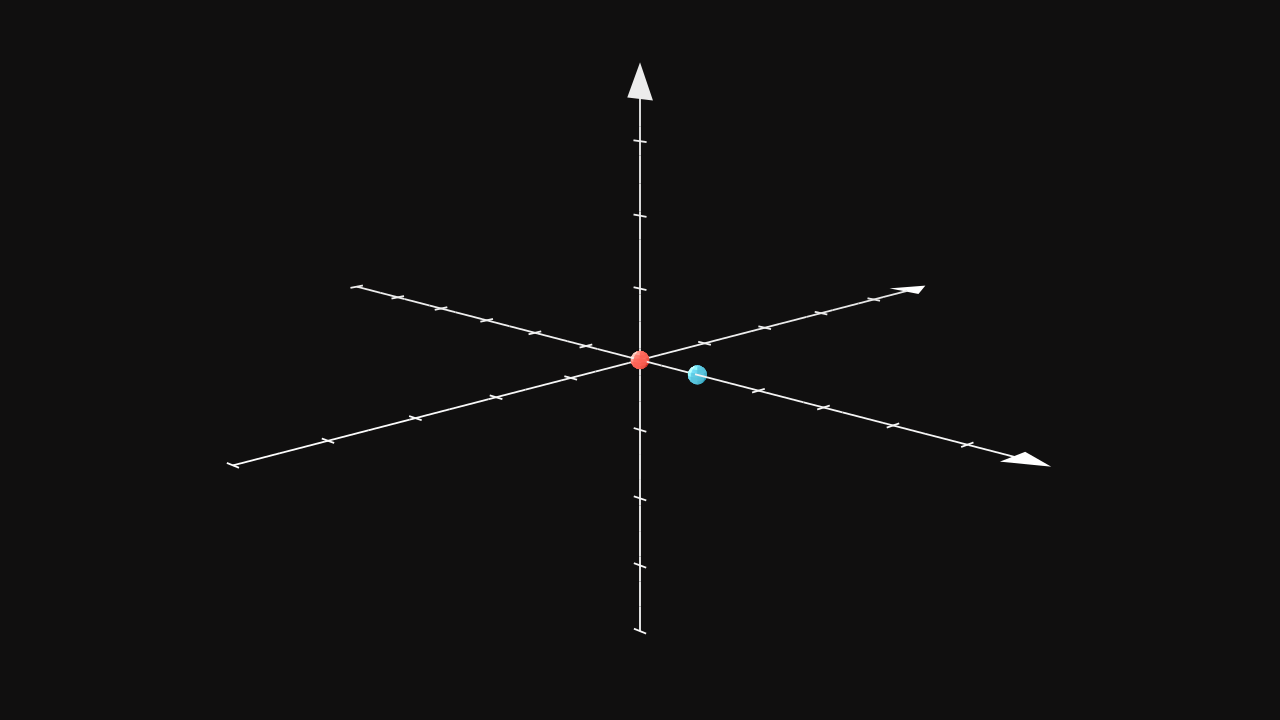
The goal of the agent (red dot) is to find the shortest path to eat the blue dot. In this example, there is no rule to restart the experience except by waiting until the agent has successfully reached the blue dot. Therefore, a maximum of attempts of actions is defined and is higher than the minimum number of actions needed to reach the objective. An episode is an experience where the agent interacts with its environment until either having reached the objective or either having used all attempts. A similar definition of an episode is the consecutive states of the environment.
Simplifying of the episode
In order to understand how the agent will learn by exploring its environment, the example is simplified to only one step to reach the objective. The agent has only one action per episode allowed. As a result, it will either succeed or either fails.
Actions
To summarize about actions, there are six discrete actions that can counted :
| Actions |
|---|
| \(A_1 = X\) |
| \(A_2 = -X\) |
| \(A_3 = Y\) |
| \(A_4 = -Y\) |
| \(A_5 = Z\) |
| \(A_6 = -Z\) |
Note in some environment, the action may be continuous which means the action is included in a range. For instance, if the action is to determine the angular position given different information from sensors, then the expected action is a number (a decimal). Whereas in this example, the output of the model is an array of probabilities of actions.
Rewards
The definition of the rewards is one of the keys of Reinforcement Learning. They denote the amount of success of the agent by taking a specific action. In this way, the agent receives positive and negatives rewards depending on its behavior.

In this example, each action can be seen as the faces of dice if we assume that the agent is not trained and there is as much as chance between all actions. The rewards are defined by the designer in such a way that the agent is led to the objective.
Note the reward is discrete (i.e. six scalar values based on actions) whereas it can be defined as the reward function. It is a function often based on the action and the environment.
Expected reward
In Reinforcement Learning, the model (the agent) has to maximize the expected reward in long term. It is the starting point for learning. The expected reward is defined as: \[ \mathbb E(R(\tau)) \] where \(\mathbb E(\cdot)\) is the expected value, \(R(\cdot)\) is the reward function and \(\tau\) is the trajectory, a set of consecutive states, actions and rewards.
A trajectory can be seen as the path taken by the agent (set of consecutive positions and directions) and the rewards obtained through this specific path.
The model of the agent \(\pi\) is called the policy. It denotes the current behavior of agent.
It is possible to compute the expected value of the policy of the agent based on the probabilities and rewards. \[ \begin{align} \mathbb E(R | \pi) &= 10 \times \frac 1 6 - 1 \times \frac 1 6 - 1 \times \frac 1 6 - 1 \times \frac 1 6 - 1 \times \frac 1 6 - 1 \times \frac 1 6 \\ &= \frac 5 6 \approx 0.833 \end{align} \]
But it can also be seen graphically. The expected reward is the area under the curve of the reward function.
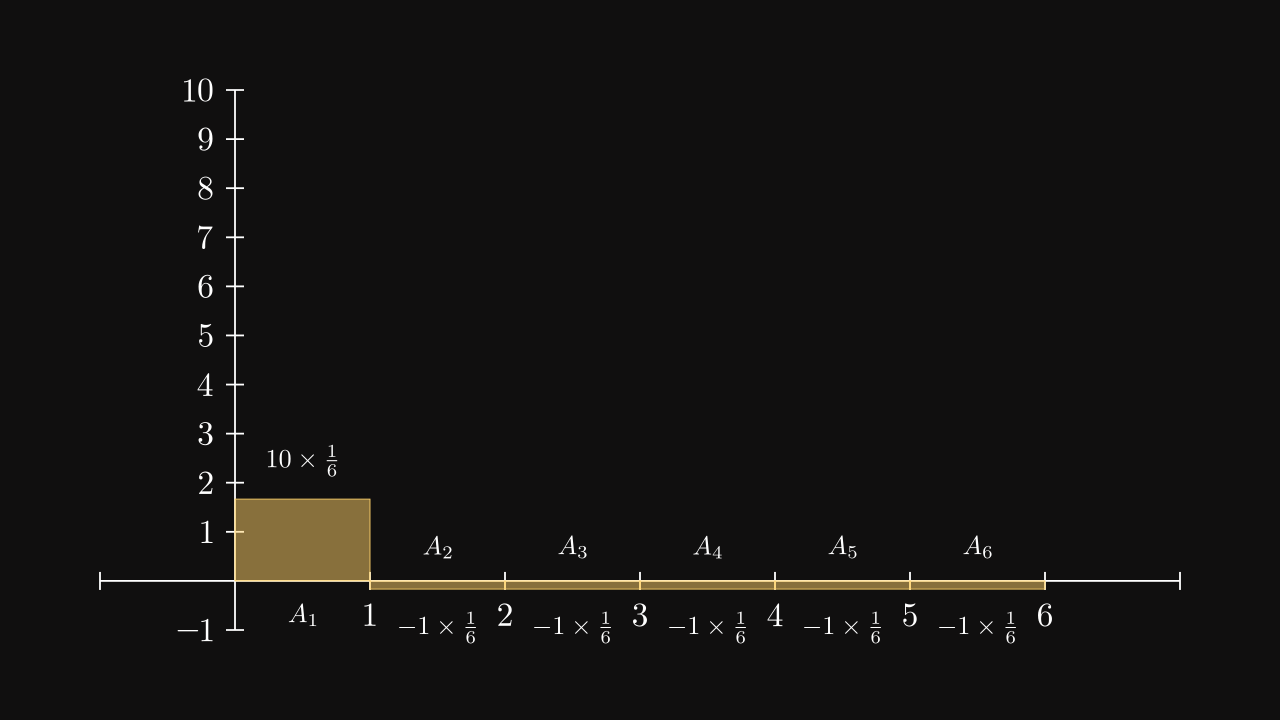
When the agent chooses different actions, it will modify the probabilities of actions based on its experience. And since its goal is to maximize the expected reward in long term, the area under the curve has to be maximized by changing probabilities.
Final result
The agent is able to maximize an expected reward based on its experience. However, the agent will find its own path to reach its objective. It means, in most of the cases, there is an infinite number of paths and the way of going through of specific path, depends on several elements:
- the environment which may cause issue depending on its definition
- the reward function which impacts considerably the behavior of the agent
- the policy which needs to be carefully designed
An ultimate important aspect of Reinforcement Learning is, although RL is a powerful way to solve problems such as games, long-term planning or robotic problems, in real world applications, the environment is dynamic, which means it changes over time. Therefore, the agent must be trained over time with new data coming from the environment. For instance, for a planning, if the agent needs to deal with a new process, it might fail if the new process is too much different from the known processes.